After we setup CgrateS the next thing we’d generally want to do would be to rate some traffic.
Of course, that could be realtime traffic, from Diameter, Radius, Kamailio, FreeSWITCH, Asterisk or whatever your case may be, but it could just as easily be CSV files, records from a database or a text file.
We’re going to be rating CDRs from simple CSV files with the date of the event, calling party, called party, and talk time, but of course your CDR exports will have a different format, and that’s to be expected – we tailor the Event Reader Service to match the format of the files we need.
The Event Reader Service, like everything inside CgrateS, is modular.
ERS is a module we load that parses files using the rules we define, and creates Events that CgrateS can process and charge for, based on the rules we define.
But before I can tell you that story, I have to tell you this story…
Nick’s imaginary CSV factory
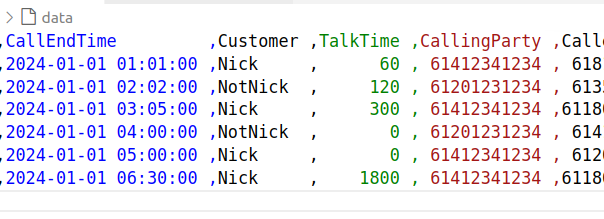
In the repo I’ve added a DummyCSV.csv, it’s (as you might have guessed) a CSV file.
This CSV file is like a million other CSV formats out there – We’ve got a CSV file with Start Time, End Time, Customer, Talk Time, Calling Party, Called Party, Animal (for reasons) and CallID to uniquely identify this CDR.

Protip: The Rainbow CSV VScode extension makes viewing/editing/querying CSV files in VScode much easier.
| Call Start Time | Row 0 |
| Call End Time | Row 1 |
| Customer | Row 2 |
| Talk Time | Row 3 |
| Calling Party | Row 4 |
| Called Party | Row 5 |
| Animal | Row 6 |
| CallID | Row 7 |
Next we need to feed this into CGrateS, and for that we’ll be using the Event Reporter Service.
JSON config files don’t make for riveting blog posts, but you’ve made it this far, so let’s power through.
ERS is setup in CGrateS’ JSON config file, where we’ll need to define one or more readers which are the the logic we define inside CGrateS to tell it what fields are what, where to find the files we need to import, and set all the parameters for the imports.
This means if we have a CSV file type we get from one of our suppliers with CDRs in it, we’d define a reader to parse that type of file.
Likewise, if we’ve got a CSV of SMS traffic out of our SMSc, we’d need to define another reader to parse the CDRs in that format – Generally we’ll do a Reader for each file type we want to parse.
So let’s define a reader for this CSV spec we’ve just defined:
"ers": {
"enabled": true,
"readers": [
{
"id": "blog_example_csv_parser",
"enabled": true,
"run_delay": "-1",
"type": "*file_csv",
"opts": {
"csvFieldSeparator":",",
"csvLazyQuotes": true,
//csvLazyQuotes Counts the row length and if does not match this value declares an error
//-1 means to look at the first row and use that as the row length
"csvRowLength": -1
},
"source_path": "/var/spool/cgrates/blog_example_csv_parser/in",
"processed_path": "/var/spool/cgrates/blog_example_csv_parser/out",
"concurrent_requests": 1024, //How many files to process at the same time
"flags": [
"*cdrs",
"*log"
],
"tenant": "cgrates.org",
"filters": [
"*string:~*req.2:Nick", //Only process CDRs where Customer column == "Nick"
],
"fields":[]
}]}This should hopefully be relatively simple (I’ve commented it as best I can).
The ID of the ERS object is just the name of this reader – you can name it anything you like, keeping in mind we can have multiple readers defined for different file formats we may want to read, and setting the ID just helps to differentiate them.
The run_delay of -1 means ERS will run as soon as a file is moved into the source_path directory, and the type is a CSV file – Note that’s moved not copied. We’ve got to move the file, not just copy it, as CGrateS waits for the inode notify.
In the opts section we set the specifics for the CSV we’re reading, field separator if how we’re separating the values in our CSV, and in our case, we’re using commas to delineate the fields, but if you were using a file using semicolons or another delineator, you’d adjust this.
Lastly we’ve got the paths, the source path is where we’ll need to move the files to get processed into, and the processed_path is where the processed files will end up.
For now I’ve set the flags to *log and *cdrs – By calling log we’ll make our lives a bit easier for debugging, and CDRs will send the event to the CDRs module to generate a rated CDR in CGrateS, which we could then use to bill a customer, a supplier, etc, and access via the API or exporting using Event Exporter Service.
Lastly under FilterS we’re able to define the filters that should define if we should process a row or not.
You don’t know how much you need this feature until you need this feature.
The filter rule I’ve included will only process lines where the Customer field in the CSV (row #2) is equal to “Nick”. You could use this to also filter only calls that have been answered, only calls to off-net, etc, etc – FilterS needs a blog post all on it’s own (and if you’re reading this in the future I may have already written one).
Alright, so far so good, we’ve just defined the metadata we need to do to read the file, but now how do we actually get down to parsing the lines in the file?
Well, that’s where the data in Fields: [] comes in.
If you’ve been following along the CgrateS in baby steps series, you’ll have rated a CDR using the API, that looked something like this:
{"method": "CDRsV1.ProcessExternalCDR", "params": [ { \
"Category": "call",
"RequestType": "*raw",
"ToR": "*monetary",
"Tenant": "cgrates.org",
"Account": "1002",
"Subject": "1002",
"Destination": "6141111124211",
"AnswerTime": "2022-02-15 13:07:39",
"SetupTime": "2022-02-15 13:07:30",
"Usage": "181s",
"OriginID": "API Function Example"
}], "id": 0}ERS is going to use the same API to rate a CDR, calling more-or-less the same API, so we’re going to set the parameters that go into this from the CSV contents inside the fields:
"fields":[
//Type of Record (Voice)
{"tag": "ToR", "path": "*cgreq.ToR", "type": "*constant", "value": "*voice"},
//Category set to "call" to match RatingProfile_VoiceCalls from our RatingProfile
{"tag": "Category", "path": "*cgreq.Category", "type": "*constant", "value": "call"},
//RequestType is *rated as we won't be deducting from an account balance
{"tag": "RequestType", "path": "*cgreq.RequestType", "type": "*constant", "value": "*rated"},
]That’s the static values out of the way, next up we’ll define our values we pluck from the CSV. We can get the value of each row from “~*req.ColumnNumber” where ColumnNumber is the column number starting from 0.
//Unique ID for this call - We get this from the CallID field in the CSV
{"tag": "OriginID", "path": "*cgreq.OriginID", "type": "*variable","value":"~*req.7"},
//Account is the Source of the call
{"tag": "Account", "path": "*cgreq.Account", "type": "*variable", "value": "~*req.4"},
//Destination is B Party Number - We use 'Called Party Number'
{"tag": "Destination", "path": "*cgreq.Destination", "type": "*variable", "value": "~*req.5"},
{"tag": "Subject", "path": "*cgreq.Subject", "type": "*variable", "value": "~*req.5"},
//Call Setup Time (In this case, CGrateS can already process this as a datetime object)
{"tag": "SetupTime", "path": "*cgreq.SetupTime", "type": "*variable", "value": "~*req.0"},
//Usage in seconds - We use 'Call duration'
{"tag": "Usage", "path": "*cgreq.Usage", "type": "*variable", "value": "~*req.3"},
//We can include extra columns with extra data - Like this one:
{"tag": "Animal", "path": "*cgreq.Animal", "type": "*variable", "value": "~*req.6"},
]Perfect,
If you’re struggling to get your JSON file right, that’s OK, I’ve included the JSON CGrateS.config file here.
You’ll need to restart CGrateS after putting the config changes in, but your instance will probably fail to start as we’ll need to create the directories we specified CGrateS should monitor for incoming CSV files:
mkdir /var/spool/cgrates/blog_example_csv_parser/
mkdir /var/spool/cgrates/blog_example_csv_parser/in
mkdir /var/spool/cgrates/blog_example_csv_parser/out
Right, now if we start CGrateS it should run.
But before we can put this all into play, we’ll need to setup some rates. My previous posts have covered how to do this, so for that I’ve included a Python script to setup all the rates, which you can run once you’ve restarted CGrateS.
Alright, with that out of the way, we can test it out, move our Dummy.csv file to /var/spool/cgrates/blog_example_csv_parser/in and see what happens.
mv Dummy.csv /var/spool/cgrates/blog_example_csv_parser/in/
All going well in your CGrateS log you’ll see all the events flying past for each row.
Then either via the CGrateS API, or just looking into the MySQL “cdrs” table you should see the records we just created.
And with that, you’ve rated CDRs from a CSV file and put them into CGrateS.
Other posts in the CGrateS in Baby Steps series:
- CGrateS Part 1 – Basics of CGrateS
- CGrateS in Baby Steps – Part 2 – Adding Rates and Destinations through the API
- CGrateS in Baby Steps – Part 3 – RatingProfiles & RatingPlans
- CGrateS in Baby Steps – Part 4 – Rating Calls
- CGrateS in Baby Steps – Part 5 – Events, Agents & Subsystems
- All the other posts tagged with CGrateS including SessionS, Attributes, Accounts & Balances, Actions & Action Plans, ActionTriggers, FilterS, StatS, Event Reader, CDR Export.